为智能应用添加知识库
如您有大量数据或者信息需要作为智能应用的"外置大脑",您需要为您的智能应用添加、维护知识库,以便于更好的使用。本篇为您介绍如何添加并维护知识库。
数据管理与存储

SenseFlow支持从本地文档上传内容,未来会拓展更多内容上传。上传后的数据会被自动切分成若干个小片段进行存储,便于高效管理。用户还可以根据需要自定义分片规则,例如通过分段标识符、字符长度等方式来控制内容的拆分方式。
增强检索能力
SenseFlow提供多种检索方式来帮助用户快速找到所需的知识内容。例如,您可以通过全文检索功能,使用关键词来召回与问题相关的内容片段。大语言模型会基于召回的片段生成更加准确的回复,提升智能体的回答质量。
有关知识库的更多详细信息,请参考知识库详细说明。
如何添加知识库
为智能体添加知识库,能够显著提升其专业性和回答的准确性。通过知识库,智能体能够更好地处理复杂查询,并减少错误信息的生成。您可以为智能体添加不同类型的知识库,包括文本知识库、表格知识库和图片知识库等。
在添加知识库之前,您需要先创建一个知识库,具体操作请参考创建知识库章节。
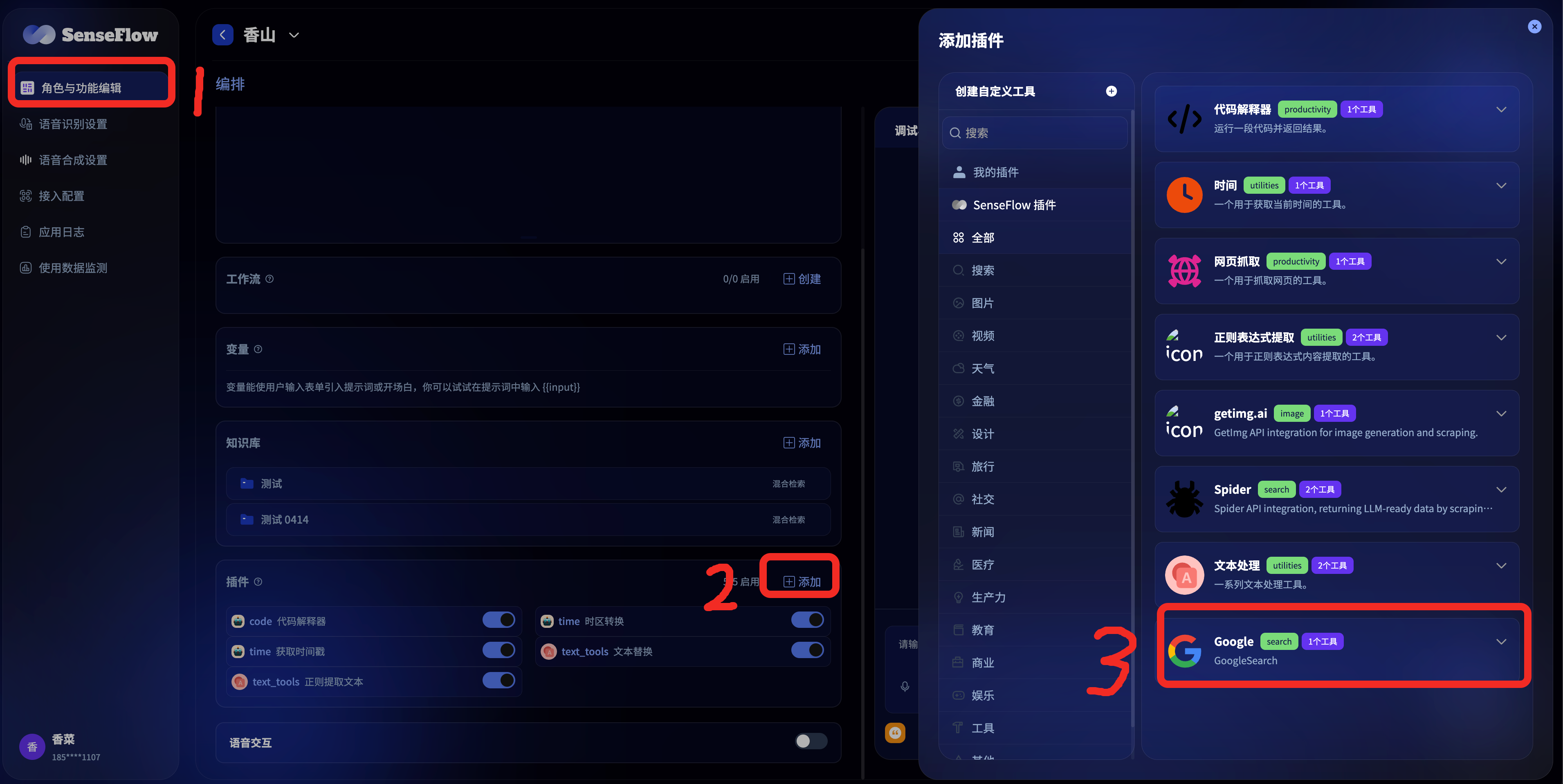
操作步骤
- 登录SenseFlow平台
- 在【工作台】页面,创建或选择一个已有的智能体
- 在角色与功能编辑页面,找到知识库,点击添加按钮(+),选择并添加需要的知识库
知识库的检索与召回
一旦为智能体关联了知识库,您就可以通过配置检索与召回策略来优化查询过程。这些配置将决定从哪里检索、如何检索以及返回多少相关内容。召回内容的质量和相关度越高,模型生成的回复就会越准确,效果也会更加理想。
操作步骤
- 在知识功能区域中,点击自动调用选项,进入配置页面
- 在配置页面中,您可以根据需求设置召回策略和搜索方式,确保知识库的内容能够有效支持智能体的回答生成
知识库检索与召回详解
什么是知识库的检索与召回?
检索与召回是指智能应用从知识库中找到相关内容片段并将其用于生成回答的过程。这一功能是知识库的核心,决定了智能体从哪里查询知识、如何查询知识,以及如何将查询结果整合到最终的回答中。
通过检索与召回,应用能够在海量知识中快速找到与用户问题最相关的内容,使其回答更准确、专业且符合用户需求。
检索过程
检索是知识库内容的查找过程。当用户向智能体提问时,系统会根据用户的输入,使用关键词、短语或语义匹配技术在知识库中查找相关的内容片段。检索的方式包括但不限于:
- 全文检索:通过关键词查找包含这些词的内容片段
- 混合检索:结合关键词匹配和语义理解等多种检索方式,实现更全面和准确的内容查找
召回过程
召回是从检索到的内容中挑选出最相关的内容片段,并将其用于生成回答的过程。召回的内容越精准、相关性越高,智能体生成的回答就越可靠。召回可以通过设定规则,比如返回与用户问题最匹配的前几条内容。
关键参数配置
Top K
在召回过程中,Top-K是一个重要的参数概念,它指定了系统从检索结果中返回的最相关内容片段的数量。例如,如果设置Top-K=3,系统会返回相关性排名最高的前3条内容。设置合适的Top-K值很重要:
- 值太小可能会遗漏重要信息
- 值太大可能会引入噪声,影响回答质量
- 一般建议根据具体应用场景,将Top-K设置在3-5之间
Score阈值(相似度阈值)
Score阈值是衡量检索内容��与用户查询相关程度的一个重要指标。系统会为每个检索到的内容片段计算一个相似度分数(Score),分数越高表示内容与查询越相关。
通过设置Score阈值,您可以过滤掉相关性较低的内容:
- 只有Score高于设定阈值的内容片段才会被召回使用
- 阈值设置过高可能导致召回内容太少
- 阈值设置过低则可能引入不够相关的内容
建议将Score阈值设置在0.6-0.8之间,具体取值可以根据应用场景和内容质量要求进行调整。这样可以在保证召回内容相关性的同时,获得足够的知识支持。
Top K与Score阈值的协同作用
Top K和Score阈值是两个相互配合的参数,共同决定了知识库召回的质量:
- 优先级顺序:系统首先应用Score阈值筛选出相关性达标的内容,然后从这些内容中选择Top K个最相关的结果
- 平衡机制:当Score阈值较高时,可以适当增加Top K值以确保有足够的召回内容;当Score阈值较低时,可以减小Top K值以控制噪声
- 动态调整:这两个参数需要根据实际应用效果进行协调调整,找到最佳平衡点
例如,如果设置Score阈值为0.7,Top K为5,系统会先筛选出相似度大于0.7的内容,然后从中选择相似度最高的5条内容用于生成回答。
最佳实践
知识库内容准备
- 内容质量:确保上传的文档内容准确、完整、结构化
- 格式标准:使用标准的文档格式,便于系统解析
- 定期更新:及时更新过时信息,保持知识库的时效性
检索参数调优
- 测试不同参数组合:通过实际测试找到最佳的Top K和Score阈值组合
- 场景化调整:针对不同的应用场景调整参数设置
- 持续优化:根据用户反馈和使用效果持续优化参数
性能监控
- 回答质量评估:定期评估智能体回答的准确性和相关性
- 检索效果分析:分析检索召回的内容是否符合预期
- 用户反馈收集:收集用户反馈,持续改进知识库配置
下一步:为智能应用添加插件